 KEI : Qu’est-ce que le Keywords Efficiency Index (ou coefficient d’efficacité de mots clés)?
KEI : Qu’est-ce que le Keywords Efficiency Index (ou coefficient d’efficacité de mots clés)?
 KEI : Qu’est-ce que le Keywords Efficiency Index (ou coefficient d’efficacité de mots clés)?
KEI : Qu’est-ce que le Keywords Efficiency Index (ou coefficient d’efficacité de mots clés)?Le coefficient d’efficacité d’un mot clé est le ratio entre le nombre de requêtes mensuelles effectuées par les internautes (c-a-d le nombre de recherches) et le nombre de page indexées (c-a-d le nombre de réponses fournies par Google).
En toute logique un bon coefficient est un grand nombre de requêtes pour une concurrence modérée sur le net et la notation d’un bon mot-clé sur la base d’un KEI (entre 1 et 10 voire plus) est :
- KEI<1 : Mot-clé sans grand intérêt
- 1<10 : Bon mot-clé
- KEI>10 : Mot-clé excellent
Comment calculer le coefficient d’efficacité de mots clés ?
Cela dépend du :
- nombre de requêtes (NRq) : Il correspond au volume mensuel de recherches pour un mot clé sur un moteur de recherche donné (donné par Google Ads dans son Générateur de mots clés).
- nombre de résultats (NRe) : Ce chiffre indique combien de réponses et donc de pages web sont déjà positionnées sur un mot clé (donné en effectuant la recherche du mot clé sur google).
La formule classique est alors :
Nrq * Nre x 1000 (ou pour certains : NRq2 * Nre)
Et qui peut être enrichie par une autre variable, la pertinence (P) : elle doit exprimer la corrélation entre le mot-clé et l’offre, le produit ou le service proposé. Il existe trois grades sur l’échelle pour mesurer la pertinence (1 pour excellent – 2 pour Bon – 3 pour mauvais).
La formule devient alors :
(4-P) * 3 x NRq2 * Nre
Qu’en conclure ?
- Moins il y a de sites déjà positionné sur un mot-clé et donc de réponses dans Google, plus le KEI de ce mot clé sera favorable en proportion du nombre de requêtes exprimés.
- Un grand nombre de requêtes, peu de concurrence et une bonne pertinence semble être la situation idéale.
Surtout que :
- Le KEI sera d’autant meilleur que l’on se basera sur des expressions exactes (mais assez logique puisque ce sont celles que Google placera en premier dans ces réponses) et que les mots clés identifiés par cette formule seront alors la liste de vos mots clés sur la longue traine…
Donc rien de nouveau et d’utile…si ce n’est une volonté de nous faire croire à une réalité scientifique pour une prestation de référencement naturel alors que le bon sens est plus souvent le meilleur moyen d’y arriver !!!
 TF-IDF : Qu’est-ce que que le Term Frequency-Inverse Document Frequency ?
TF-IDF : Qu’est-ce que que le Term Frequency-Inverse Document Frequency ?
 TF-IDF : Qu’est-ce que que le Term Frequency-Inverse Document Frequency ?
TF-IDF : Qu’est-ce que que le Term Frequency-Inverse Document Frequency ? C’est une méthode statistique de pondération qui permet d’évaluer l’importance d’un mot clé contenu dans un document textuel. Le poids de ce ratio augmente proportionnellement avec le nombre d’occurrences du mot clé dans le texte et varie en fonction de la fréquence à laquelle il apparaît dans d’autres documents sur Internet : le « corpus ».
La fréquence d’un mot clé (Term Frequency) est simplement le nombre d’occurrences de ce mot clé dans le document analysé tandis que la fréquence inverse du document (Inverse Document Frequency) mesure l’importance du mot clé dans l’ensemble du texte.
L’objectif est de déterminer la pertinence lexicale d’une page pour une requête sur Google.
Comment se calcule le TF-IDF ?
en fait par la multiplication des deux valeurs TF et IDF entre elles: TF x IDF
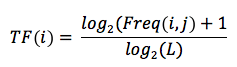 i : mot clé dont le Term Frequency déterminé dans le document
i : mot clé dont le Term Frequency déterminé dans le document
j : document analysé
i,j : nombre total de mots dans le document « j »
Freq(i,j) : fréquence d’un mot « i » dans le document « j »
Log2 : logarithme du nombre x en base 2
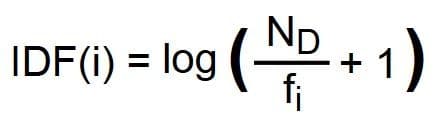 i : terme dont l’Inverse Document Frequency doit être déterminée
i : terme dont l’Inverse Document Frequency doit être déterminée
Log : logarithme du nombre x en base 10 ou en toute autre base b
ND : nombre de tous les documents dans le corps du document (qui contiennent les termes pertinents)
fi : nombre de tous les documents dans lesquels le terme « i » apparaît
L’avantage de l’utilisation du TF-IDF est principalement qu’il permet de surveiller le bourrage de mots-clés existants (sur optimisation) tout en privilégiant la pertinence lexicale des textes utilisés et la singularité des fréquences de mot clé utilisées.
En revanche, cette méthodologie a plusieurs limites pour le référencement :
- Elle ne prend pas en compte les synonymes,
- en s’appuyant sur la « pondération brute » c-a-d quantitative des mots clés évaluée sur l’ensemble du document, elle ne prend pas en compte la hiérarchie des utilisations qui en a été faite pour le SEO (balises titres, balises Hn, alt, url, strong…) et qui est quand même primordiale pour les critères de Google,
- enfin, pour calculer cette fréquence, il faut arbitrairement choisir des textes du corpus : on peut alors se baser par exemple sur les 10, 20 ou 50 premiers documents indexés par Google avec un mot clé précis, mais il faudrait aussi ne prendre que les pages données avec 0 backlinks, permettant ainsi d’obtenir les textes bruts et 100% pertinents algorithmiquement.
En conclusion, une méthode d’analyse sophistiquée et souvent imaginée utilisée par les algorithmes des moteurs de recherche, mais qui, dans une optique de prestation SEO ne semble pas primordiale.
Utilisée avec modération par les agences de référencement naturel, elle permet avant tout de se constituer une base de réflexion quant à l’évaluation de la qualité et la quantité lexical des mots clés : quels mots-clés mettre en avant, créer des textes le plus unique possible, connaitre les thématiques associées, utiliser la construction en silo, et tester les mots clés de la longue traine.
Mais n’oubliez pas qu’il est préférable de se concentrer sur du contenu textuel qui aura une qualité informationnelle auprès des internautes au lieu de se focaliser sur des considérations expérimentales et mathématiques, et ce sera alors de la pertinence « naturelle », peut-être bien plus efficace !
Une réponse à “KEI & TF-IDF : des acronymes SEO utiles?”
[…] valoriser, identifier les mots clés, des outils calculs statistiques et/ou mathématiques (KEI, TF-IDF,…), bref une panoplie de solutions pour arriver à cet objectif : essayer de trouver […]